The Stream AI Protocol: Technical Architecture
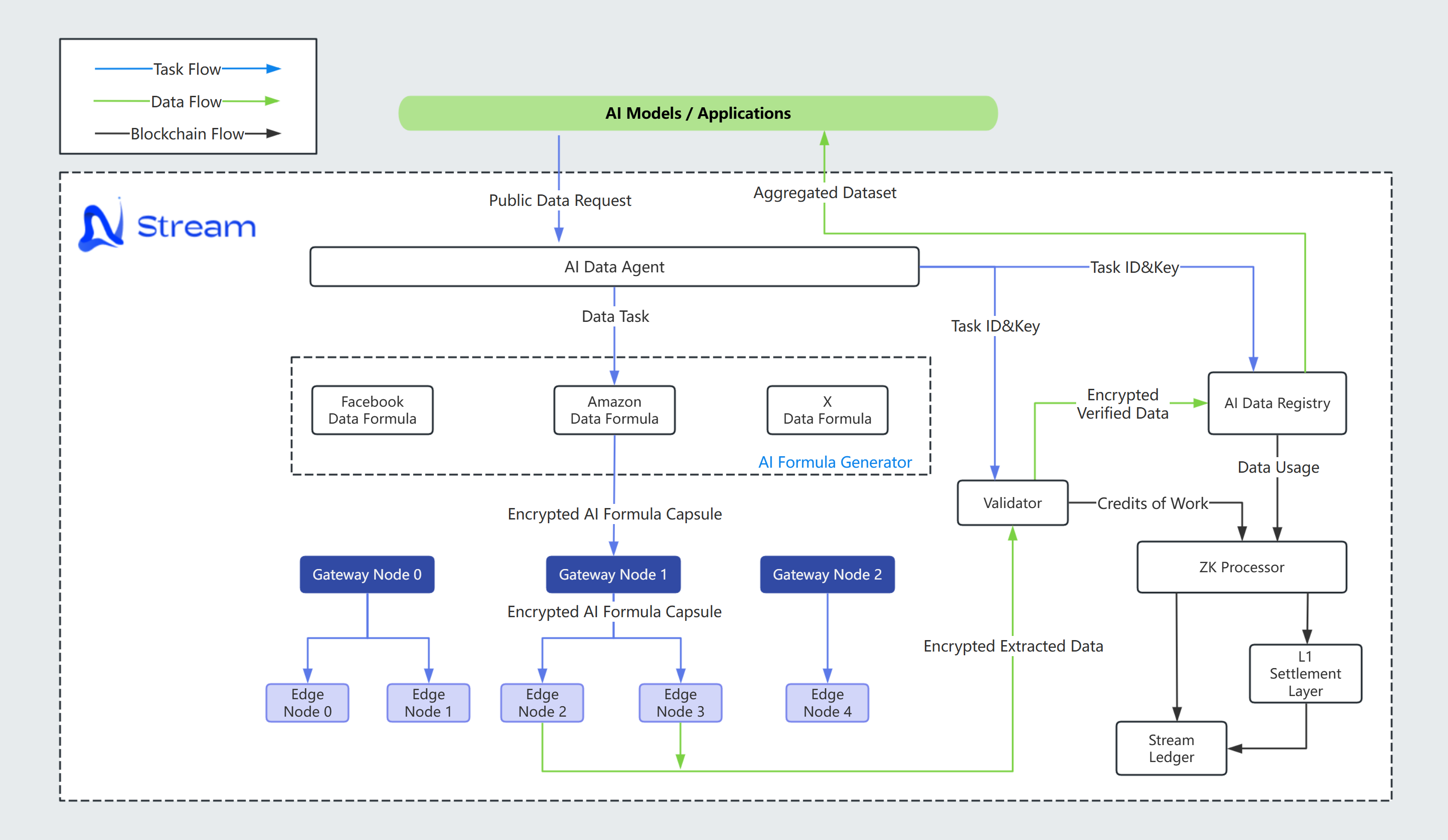
Network Topology
The Stream AI network employs a hierarchical structure to optimize data flow and task distribution:
a) Edge Nodes (ENs): Form the base layer of the network, responsible for executing scraping tasks and initial data processing.
b) Gateway Nodes (GNs): Act as intermediaries between Device Nodes and the wider network, managing task distribution and data aggregation.
c) Validator: Overseeing network integrity and data quality.
d) AI Data Agent: Receive and understand public data requests from AI Models/Applications, make judgement, choose the existing Data Formula or Generate a new Data Formula.
Task Distribution and Execution
The process of data collection and processing in the Stream AI network follows these steps:
1.Task Creation: AI Data agent receive and understand public data requests from AI Models/Applications, create the data collection task.
- Data Formula Generation: AI generate the requested Data Formula, including task identifier, target URL and executable parser.
3.Task Distribution: Gateway Nodes break down tasks into smaller, manageable requests and distribute them among available Edge Nodes.
4.Task execution: Edge Nodes execute Formula tasks, extract requested public data from assigned sources.
5.Validation: Validator Nodes verify the integrity and quality of the collected data. The proofs will be processed to the Stream Ledger.
6.Data Registry: Verified data is added to the Stream AI Data Registry, stored in decentralized Vector Database, ready for AI consumption.
7.Data Aggregation: The AI Data Registry aggregates the requested public data and generate AI datasets according to Task ID, empower AI Models/Applications for training or RAG building.
Privacy and Security Measures
Stream AI implements robust privacy and security measures to protect both network participants and data sources:
a) Anonymized Contributions: Device Nodes contribute resources anonymously, preserving user privacy.
b) Encrypted Data Transfer: All data transferred within the network is encrypted end-to-end.
c) Ethical Scraping Practices: Adherence to robots.txt files and website terms of service to ensure ethical data collection.
d) Decentralized Storage: Collected data is stored across the network, minimizing the risk of large-scale data breaches.